金融信創(chuàng)產(chǎn)業(yè)雙報(bào)告發(fā)布 數(shù)字科技服務(wù)商如何賦能金融機(jī)構(gòu)轉(zhuǎn)型
零壹研究院院長于百程發(fā)布了《數(shù)字科技服務(wù)商賦能金融信創(chuàng)產(chǎn)業(yè)發(fā)展報(bào)告》,聚焦數(shù)字技術(shù)服務(wù)在金融信創(chuàng)領(lǐng)域的應(yīng)用與實(shí)踐。該報(bào)告系統(tǒng)闡述了數(shù)字科技服務(wù)商在金融信息技術(shù)應(yīng)用創(chuàng)新(信創(chuàng))背景下的角色定位、技術(shù)路徑與市場趨勢,為金融機(jī)構(gòu)的數(shù)字化轉(zhuǎn)型提供了重要參考。
報(bào)告指出,隨著金融行業(yè)對(duì)自主可控、安全高效的技術(shù)需求日益增長,金融信創(chuàng)已成為國家戰(zhàn)略的重要組成部分。數(shù)字科技服務(wù)商作為連接底層技術(shù)與金融業(yè)務(wù)場景的關(guān)鍵橋梁,正通過云計(jì)算、大數(shù)據(jù)、人工智能、區(qū)塊鏈等前沿技術(shù),幫助金融機(jī)構(gòu)構(gòu)建安全、穩(wěn)定、敏捷的數(shù)字化基礎(chǔ)設(shè)施。
在技術(shù)層面,報(bào)告強(qiáng)調(diào)數(shù)字科技服務(wù)商需具備全棧技術(shù)能力,覆蓋從底層硬件適配、操作系統(tǒng)優(yōu)化,到中間件、數(shù)據(jù)庫、應(yīng)用軟件的全面解決方案。特別是在分布式架構(gòu)、云原生、隱私計(jì)算等領(lǐng)域,服務(wù)商通過自主研發(fā)或生態(tài)合作,助力金融機(jī)構(gòu)實(shí)現(xiàn)核心系統(tǒng)的平滑遷移與創(chuàng)新應(yīng)用落地。
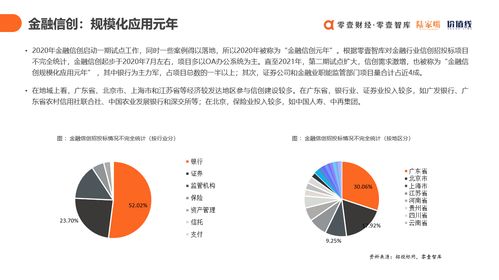
市場方面,報(bào)告顯示金融信創(chuàng)產(chǎn)業(yè)已進(jìn)入規(guī)模化推廣階段,銀行、證券、保險(xiǎn)等機(jī)構(gòu)正加大信創(chuàng)投入。數(shù)字科技服務(wù)商不僅提供產(chǎn)品與技術(shù),更需深入業(yè)務(wù)場景,結(jié)合合規(guī)要求與行業(yè)特性,為金融機(jī)構(gòu)提供咨詢、交付、運(yùn)維等全生命周期服務(wù),形成“技術(shù)+業(yè)務(wù)”雙輪驅(qū)動(dòng)模式。
于百程認(rèn)為數(shù)字科技服務(wù)商應(yīng)持續(xù)強(qiáng)化自主創(chuàng)新能力,深化與金融機(jī)構(gòu)的協(xié)同合作,共同應(yīng)對(duì)數(shù)據(jù)安全、系統(tǒng)兼容、生態(tài)建設(shè)等挑戰(zhàn)。隨著金融信創(chuàng)標(biāo)準(zhǔn)體系逐步完善,服務(wù)商需積極布局開源生態(tài)與行業(yè)標(biāo)準(zhǔn)制定,推動(dòng)產(chǎn)業(yè)鏈上下游協(xié)同發(fā)展,為金融業(yè)高質(zhì)量發(fā)展注入數(shù)字動(dòng)能。
該報(bào)告的發(fā)布,為金融信創(chuàng)產(chǎn)業(yè)的參與者提供了清晰的行動(dòng)指南,凸顯了數(shù)字技術(shù)服務(wù)在提升金融行業(yè)競爭力、保障國家金融安全中的戰(zhàn)略價(jià)值。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.gdzyzx.com.cn/product/46.html
更新時(shí)間:2026-06-19 08:55:04